Прикладной уровень
Минимальной единицей исполнения в Windows является поток (thread), который в каждый момент времени может исполняться только на одном процессоре. Несмотря на то, что в большинстве случаев этот процессор не является жестко закрепленным и планировщик может запускать поток на любом свободном процессоре, поток остается неделимым (как атом), и различные части потока никогда не выполняются более, чем на одном процессоре одновременно. То есть, если в системе запущено только одно однопоточное приложение, на многопроцессорной машине оно будет выполняться с той же самой скоростью, что и на однопроцессорной (или даже чуть медленнее, за счет накладных расходов на поддержку многопроцессорности).
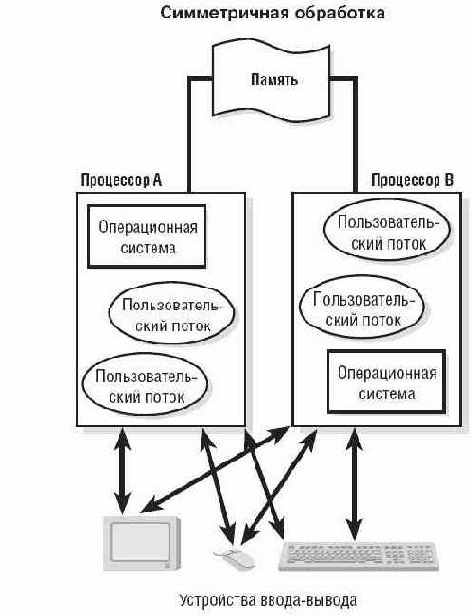
Рисунок1 в симметричной многопроцессорной системе (которой является Windows NT и ее потомки), каждый поток может исполняться на любом процессоре
Процесс — более крупная исполнительная единица. Грубо говоря, это "коробок", в котором находятся принадлежащие ему потоки, исполняющиеся в едином адресном пространстве. Каждый поток обладает своим собственным стеком и набором регистров, но вынужден разделять глобальные переменные и динамическую память вместе с другими потоками процесса, что порождает проблему синхронизации. Допустим, один поток выводит ASCIIZ строку на экран, а другой — в это же самое время выполняет над этой строкой функцию strcat(), удаляющую символ нуля до завершения операции копирования. Как следствие — первый поток "вылетит" за пределы строки и пойдет чесать напаханную область памяти до тех пор пока не встретит посторонний нуль или не нарвется на исключение типа access violation.
Предотвратить такую ситуацию можно двояко. Либо переписать strcat() так, чтобы она сначала дублировала символ нуля, а только потом замещала его символом копируемой строки, либо воспользоваться один из средств синхронизации, например, критической секций, фактически представляющий собой флаг занятости. Поток, копирующий строку, взводит этот флаг перед вызовом strcat(), а поток, выводящий ее на экран, проверяет состояние флага и при необходимости ждет пока тот не освобождается и тут же взводит его вновь, чтобы во время вывода строки никто другой не вздумал ее модифицировать.
В первом случае, требуется всего лишь переделать strcat(), а во втором — скоординировать действие нескольких потоков, малейшая небрежность в синхронизации которых оборачивается либо неполной синхронизацией (например, поток, выводящий строку на экран не взводит перед этим флаг занятости), либо взаимоблокировкой (когда два или более потоков ждут освобождения друг друга, но никак не могут дождаться, поскольку один из них взвел флаг занятости и забыл его сбросить). К сожалению, при работе со сложными структурами данных без механизмов синхронизации обойтись уже не получается. Синхронизующий код как бы "размазывается" по всей программе и проверить его работоспособность становится очень трудно. Отсюда и ошибки.
С Linux/BSD в этом плане дела обстоят намного лучше. Основной единицей выполнения там является процесс (поддержка потоков уже появилась, но так и не сыскала большой популярности). Процессы исполняются в раздельных адресных пространствах и могут обмениваться данными только через явные средства межпроцессорного взаимодействия, значительно упрощая задачу синхронизации.
Теперь поговорим о том, почему на однопроцессорных машинах ошибки синхронизации проявляются значительно реже, чем на многопроцессорных. Дело в том, что при наличии только одного процессора, потоки выполняются последовательно, а не параллельно. Иллюзия одновременного выполнения создается лишь за счет того, что каждый поток работает в течении очень короткого (с человеческой точки зрения) промежутка времени, называемого квантом, а потом системный планировщик передает управление другому потоку. Длительность кванта варьируется в зависимости от множества обстоятельств (подробнее этот вопрос рассмотрен в статье "разгон и торможение Windows NT"), но как бы там ни было, квант — это целая вечность для процессора, за которую он очень многое успевает сделать.
Рассмотрим следующую (кстати, вполне типичную) ситуацию. Поток вызывает какую-нибудь функцию из стандартной библиотеки Си, а затем считывает глобальную переменную errno, в которую функция поместила код ошибки.
В многопоточной программе, выполняющийся на однопроцессорной машине такая стратегия работает довольно уверенно, хотя и является порочной. Существует угроза, что поток будет прерван планировщиком после завершения Си-функции, но до обращения к переменной errno, и управление получит другой поток, вызывающему "свою" Си-функцию, затирающую прежнее содержимое errno. И, когда первый поток вновь получит управление, он увидит там совсем не то, что ожидал! Однако, вероятность этого события на _однопроцессорной_ машине крайне мала. Тело потока состоит из тысяч машинных команд и переключение контекста может произойти где угодно. Чтобы попасть между вызовом Си-функции и обращением к errno это надо очень сильно "постараться".
А вот на многопроцессорной системе, где несколько потоков выполняются _параллельно_ вероятность одновременного вызова Си-функций значительно повышается и тщательно протестированная (на однопроцессорной машине), проверенная и отлаженная программа начинает регулярно падать без всяких видимых причин!